
Ansible, part II – modules and ad-hoc commands

Sending ad-hoc commands is very simple and at the same time opens up many very useful possibilities. Thanks to them, we can conveniently issue single command on one or many nodes. Issuing such commands allows among others: querying for various statuses, compliance verification, configuration backup, node or service restart, file, package and user accounts management, software upgrade and even periodic password change.
To issue ad-hoc commands, use the “ansible” command:

- [pattern] – inventory matching pattern that was described in detail in the previous article.
- [module] – the name of the module.
- [module options] – options and arguments for the used module.
Ansible configuration file located below assumes, that we connect to all hosts using the “ansible” user without entering a password. This requires, that you first generate a key pair on the managing host for the SSH service and then send the public key to the appropriate location on the “ansible” user account of the managed nodes. After logging in, the “root” user rights are escalated using “sudo” without entering any password. Appropriate configuration of the sudo service on managed nodes is required for this purpose but as we focus only on Ansible, we skip these elements.
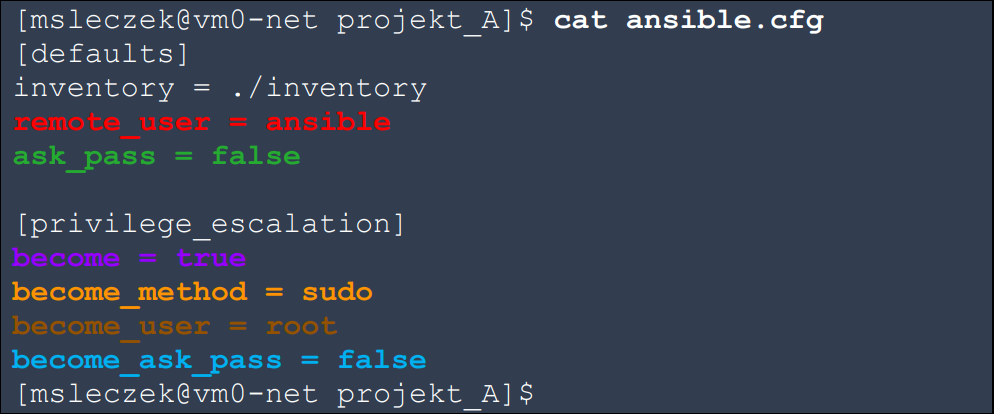
Our inventory file is very simple. It has 4 IPv4 addresses for servers with the RHEL8 system.

Most often, the INI format file is used to build the inventory. We will also use it in most examples. Its simplest form is a list of IP addresses and domain names (one per line).

Before we start, let’s see if we can manage remote nodes. The “ping” module is used to verify the ability to manage remote nodes. This module checks whether it can login to them and escalate permissions, as well as verifies the availability of Python. In fact, it requires the remote node to have Python installed. If everything goes correctly, it returns “pong” by default. This module does not generate any ICMP packets.

Ansible uses modules to perform specific tasks on hosts. When we use ad-hoc commands and do not provide the module name, the “command” module will be used by default. It executes a binary file on the remote node. Its operation is not affected by any shell environment variables. It does not use the remote system shell at all. It only executes the indicated binary file with the given arguments and returns the formatted result of its execution to us. Examples of explicit and implicit use of the “command” module are shown below:

When we log in via SSH, the commands entered in CLI are first interpreted by the shell. This is the reason why we need to precede some special characters using backslash “\” or use appropriate comments when we want to pass them as a command argument. These characters include “<“, “>“, “|“, “;” and “&“. The “command” module does not use the shell. Hence, any special shell characters will be passed directly to the command as an argument. Therefore, it is not possible to use operators and pipes provided by the shell. This is seen in the example below, where both “|” and “grep” and “sda1” were passed as arguments to the “df” command. When we give additional arguments for the “df” command, it shows information about the file systems on which the files provided as command arguments are located.

In order to better direct our attention, Ansible uses different colors in the returned results. These include:
- “task failed”,
- “made changes”,
- “nothing had to be done”.
The “command” module also has no access to any user shell environment variables, like “$HOSTNAME“, so its operation cannot use them. This has the advantage that there is no negative impact of these variables and environment settings on the used commands. This is also the reason why it is the safest and recommended way to issue ad hoc commands.
In many places you can find that the environment variable “$HOME” will not be available for the “command” module which is not correct. Actually, some environment variables, such as “$HOME“, “$SHELL” and “$PATH“, are set by the “login” program in the GNU/Linux system and available to the “sshd” process while establishing an SSH session. They can be accessed even before we execute any command to activate the shell. Thus the “command” module has access to them. However, other variables that are activated after the shell has been started, as for example “$HOSTNAME” are not available for the “command” module.
Where we need pipes, operators or shell environment variables, we should use the “shell” module. This module uses the “/bin/sh” shell by default, but this can be changed. At the same time, it is worth remembering that the result of this module may depend on the values of shell environment variables. Thus, a person modifying shell environment files may intentionally or unintentionally contribute to something that should not happen.
That is why we recommend using the “command” module to ad-hoc commands wherever this is possible.
Keep in mind that the shell can be activated in a variety of ways, and this affects how environment variables are set. If during the login, the interactive shell is activated or we do it manually by issuing the command “bash -l” or “bash –login“, then the file “/etc/profile” is executed first, followed by the first available file from the list with the order: “~/.bash_profile“, “~/.bash_login” or “~/.profile“. For an interactive shell that is not a login shell, only the “~/.bashrc” file is executed. However, there is also a non-interactive shell (“bash -c“) to which Ansible get access through the “shell” module. At startup, it executes the file under the “$BASH_ENV” variable. This variable is empty by default, so many people are surprised when they tell the “shell” module to use the bash shell, and it doesn’t see the variables defined in their environment files.
The “command” and “shell” modules require Python on the managed node. This is not always possible, although most server systems already have it right after installing the base system. The same applies to new good quality network devices. However, we will definitely come across some older devices or systems where Python will not be available, and it would be good to manage them with the same tool. This is possible thanks to the “raw” module, which bypasses the entire subsystem of Ansible modules. He issues the commands directly after establishing the SSH connection, and then sends the result back to us. This module does not make any attempt to interpret the result or error checking. We’ll get whatever is thrown at the output of STDERR and STDOUT.
Below, using the “shell” and “raw” modules for our system gave a similar result. In both cases provided command was executed in the shell “/bin/sh“. More differences should be observed in other examples.

Some Ansible modules require additional arguments and some don’t. If you are not sure how to use the module, it’s best to use the “ansible-doc” command. An example of the information it provides for the “ping” module can be seen below.

According to the “ansible-doc” for the “ping” module, the default “pong” value can be changed with the “data” argument.

Above we use extended arguments, where “-a” is equivalent to “–args” and “-m” to “–module-name“.
You can check the list of modules and plugins supported by your system by using:
![]()
The list is quite long, but it can be searched, as shown below. Manually added modules are also visible in the list. Below you can see the “cisco_webex” module that we made, which allows you to send messages into the room at Cisco Webex Teams.

It is also possible to generate an example configuration snip for a given module, which can be used as an introduction to further configuration. This is done using the command:

Ansible tasks can be run once or cyclically on a scheduled basis. Thanks to the ability to send messages to Cisco Webex Teams, we can quickly notify the appropriate team about any failures or detected incompatibilities.
We will now take care of some useful options for the “ansible” command. First, we will go one level below in the directory tree structure, so that our default settings values from the “ansible.cfg” file no longer work.

Above you can see the error, because by default Ansible tries to use the current user’s name when logging into the remote host. Earlier, we used the “ansible” user for this purpose. We can specify it manually using the “-u” or “–user” option.

After providing the correct user we can see that we do not get an error and the “whoami” command returns the user “ansible“. When we add the “-b” or “–become” option, the “whoami” command will be issued only after the privilege escalation. As a result, in the next two examples above, it returns the user “root“.
In some cases, it may be more readable or useful to put the entire result on one line. This can be done with the “-o” or “–one-line” option.

While the use of the “command“, “shell” and “raw” modules is easy and convenient, we should avoid them wherever possible. Ultimately, we should use dedicated modules specialized for specific tasks, whose purpose is to bring devices, systems, files, applications or services to the desired state, which is described in a declarative language. This means that we only specify the state that we want the object to assume, without describing in detail how this should be done. The modules that are appropriate for the specific tasks are already dealing with the rest. Depending on the initial state of the object, such a module can perform more or less different operations on it, or even not perform any, if it is not needed. This approach is characterized by idempotence, which here is the ability to repeatedly run the same module without changing the final state of the object.
It also means that we can execute the same specialized module on a given object many times. If it is already in the desired state, then nothing will happen, and if it is not, it will be brought to desired state.
It should be remembered that idempotence is guaranteed only if we use specialized and built-in modules. If we create them ourselves or use other methods, such as sending commands by the “command“, “shell” or “raw” modules, then we have to take care of idempotence ourselves.
Ansible supports a very large number of specialized modules, and their number is constantly growing. Full list is available in the Ansible documentation. Red Hat also provides additional modules and plugins in its Automation Hub. Let’s look at just a few here.
Sometimes we need to update the entire file containing the list of NTP servers, the keys used for authentication or environment variables. Ansible is perfect for this. Before doing anything, it checks if the file exists and its contents. If file exists and its content is the same, it does nothing. If not, it performs the appropriate operations. It is even able to make a copy of the previous version of the file.
Let’s assume that we want to update or standardize environment variables on a huge number of servers. Just in case, we also want to make a copy of the previous version of the file if its contents were different.

You can see above, that on two servers Ansible didn’t have to do anything. On the other two, the content of the desired file has been unified.
Instead of pointing to the source file with the “src” option, you can directly define the content that the file should have. The “content” suboption is used for this purpose.

Below you can see what the user sees after logging in to our servers:

Now let’s assume that we want to create a directory with specific permissions on all managed servers, where we will put backup copies of selected files in the future:

A lot depends on our ingenuity and knowledge of what we automate. For example, the same module can be used to disable the history of commands issued in the MySQL/MariaDB database:

As a result of the above two tasks, the “backup” directory and the “.mysql_history” symbolic link to “/dev/null” appeared on the server:

Finally, we encourage you to familiarize yourself with the “setup” module, which collects and provides a very large amount of information about each of the managed nodes. There is so much information, that we do not put it in the article. For this we refer you to check it yourself. To do this, you can use the command:
![]()
The information provided by the “setup” module can be conveniently filtered and narrowed using the appropriate suboptions. The best way is to read the “ansible-doc” for this module. Below is an example of a filter that allows you to check the operating system family and processor type.

Ad-hoc commands are just as easily run on one or hundreds of nodes.
10:45 AM, Jun 23
Author:

CEO, Network Engineer and System Administrator at networkers.pl
Marcin Ślęczek
Marcin works as CEO, Network Engineer and System Administrator at networkers.pl, which designs and implements IT Systems, Data Centers and DevOps environments. networkers.pl also sells software and hardware for building such environments and is a partner of well-known manufacturers such as Red Hat, Cisco Systems, IBM, Storware and VMware.