
Why to choose Red Hat Enterprise Linux 8?

No one likes renovations. Changes in IT systems and data centers will continue to be more and more noticeable and expensive. The reason for this is the increasing complexity of these environments, as well as the growing amount of data, services and applications.
This year, on May 7 2019, the 8th version of Red Hat Enterprise Linux (RHEL) was released. While this version can be upgraded for free as part of your existing RHEL subscription, we encourage you to choose the RHEL8 system as the basis for building new IT systems and data center environments. One of the reasons for this recommendation is the Red Hat 10-year support and the possibility of its extension after this period (the so-called Extended Life Phase)¹.

The new version of the RHEL system is not only newer versions of services, software and libraries for built applications. With the current use of virtualization and containerization, these elements are less important in the decision-making process of updating or changing the base system in IT environments and data centers.
Features and capabilities that improve performance, security, stability, scalability, and convenient operation of the environment are important. We will write more about several of them in the following parts of this article. They will include, among others:
- high-performance packet processing at the network card level with XDP and eBPF,
- higher throughput and lower latency thanks to the BBR algorithm for TCP,
- new support for packet classification and filtering (nftables instead of iptables, ip6tables, ebtables and arptables),
- greater security and automation of the DNS service (CDS/CDNSKEY, DNS Cookies and Catalog Zones),
- e-mail protection in accordance with the decision of the EU on 11 December 2017 (DNSSEC and DANE),
- greater security and easier compliance,
- more efficient and secure graphic environment (GNOME and Wayland),
- recording of administrative sessions (terminal session recording),
- web-based management interface (Cockpit and its integration with Red Hat Satellite),
- simplified support for advanced disk system functions,
- better use of disk space in XFS,
- better handling of software packages (modules, streams and DNF technology),
- more functional and safer support for containers and images (Podman, Buildah, Skopeo, UBI and Image Builder).
Along with RHEL8, the new opportunities have been emerged, such as central cloud verification of compliance with vulnerabilities, reporting and comparison of systems registered in Red Hat Insights, Red Hat Satellite and Red Hat OpenShift. This can be done centrally in one place via Red Hat Cloud Management Services, which is available at cloud.redhat.com.
It is worth remembering that Red Hat Insights is available for free as part of all RHEL subscriptions. It provides proactive analytics with ready-made procedures to remove security vulnerabilities and increase the efficiency and stability of Red Hat products. It correlates the events occurring in the system and its configuration with the information contained in the Red Hat Knowledge Base, providing information on potential problems and vulnerabilities. Red Hat Insights also has the ability to generate ready-made Ansible playbooks that are able to implement the proposed recommendations on a selected group of systems.
Just like its predecessor RHEL7, the new RHEL8 system has very good integration with Microsoft Active Directory and has a lot of tools to diagnose and monitor the current and historical system performance. Examples of these are the sysstat and PCP (Performance Co-Pilot) tools. Many other solutions lack such things, which is why we are blind with them to what is happening and doomed to the manufacturer’s support and diagnosis.
High-performance packet processing at the network adapter level with XDP and eBPF
XDP (eXpress Data Path) allows you to run eBPF (extended Berkeley Packet Filter) program in the network adapter driver area.
XDP and eBPF are two new elements of RHEL8. eBPF allows running in the Linux kernel small programs (bytecode) created in user space. These programs are run in a dedicated virtual machine that attaches to hooks in the kernel. XDP adds the additional hooks for eBPF that is directly in the network adapter driver. Thus, eBPF provides flexible kernel programming functions for processing and analyzing network packets, and XDP provides very efficient network processing functions.
Thanks to XDP/eBPF, packet filtering or other functions performed on them can be implemented immediately after the packet reaches the network card. It bypasses the entire Linux kernel stack, which allows you to filter and search a very large amount of traffic. Tests from 2017, which were described at LWN², shows the possibility of rejecting 28Mpps and modifying 10Mpps using one CPU and one network card with a speed of 40Gbps.
This combination can be used in the implementation of anti-DDoS services. Facebook and CloudFlare already use it in production. An interesting comparison of XDP against other mechanisms has been described on the CloudFlare blog³.
Another application of these technologies can be found in L4 Load Balancers. Facebook even open-sourced they Load Balancer solution called katran⁴, which uses XDP/eBPF.
In both presented applications, XDP/eBPF are great for analysis, monitoring, protection and load distribution of traffic directed not only to large networks, but also to a large number of virtual machines and containers. This is confirmed by the Open Source project called Cilium⁵, which bases its operation in the area of load distribution and security of container applications on XDP/eBPF.
Transferring some packet operations directly to network adapters is also a good step towards NFV (Network Function Virtualization) solutions such as Cisco Enterprise NFV and improving the performance of cloud and container environments, such as Red Hat OpenStack and Red Hat OpenShift.
It should be remembered that XDP and eBPF only opens up cerstain possibilities that will be used to build new solutions over time. RHEL8 is ready for it!
Higher throughput and less latency thanks to the BBR algorithm for TCP
The transmission speed is largely determined by congestion control algorithms. A CUBIC is a commonly used congestion handling algorithm in the TCP (Transmission Control Protocol). The window size used in TCP transmission is a cubic function since the last congestion. The zero point/inflection point of this function is the size of the window before congestion. An example of a cubic function has been shown below.
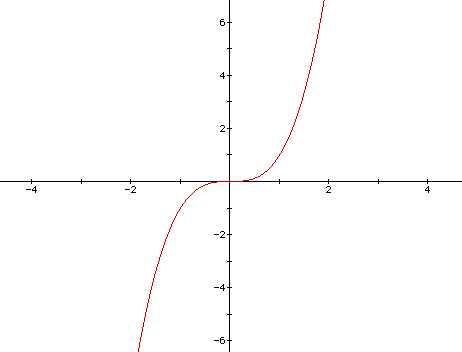
It has concave (concave downward) and convex (concave upward) space. Concave gives the ability to quickly return the window size, to the size which is close to the last congestion in the network and further slow growth to this place (previous window size). In this way, the network gets time to stabilize. Next it moves to the convex part, which is initially growing slowly and accelerates more and more if there are no signs of congestion.
Receipt of double acknowledgment (duplicate ACK) or lack of acknowledgement in RTO (Retransmission TimeOut) is recognized by CUBIC as a congestion symptom in the network. While this fact usually means that packet has been lost, it does not necessarily indicate a congestion on the network. For example, on a 10Gbps link 0.01% of packets may be lost for other reasons than link load, so slowing down the transmission rate every time one packet will be lost, may not make sense in such case.
The use of CUBIC in TCP also contributes to the full saturation of the interface buffers of network devices, and thus increases the delay. The CUBIC algorithm does not take into account RTT (Round Trip Time), hence neither low nor long delay connections are favored. They have the same chance of growth. A sudden increase in delays for all connections has a negative impact on the operation of applications requiring low latencies to work. The larger the buffers, the greater the delays.
Summing up the operation of the CUBIC algorithm in TCP, a small buffer size can lead to fast misinterpretation of congestion in the network and a significant decrease in transmission speed, and large buffer size can lead to significant increase in delays.
The buffers in current network devices are increasing, so the process of detecting congestion in the network should take into account the increase in latency. On the other hand, an algorithm based only on delays would not be treated fairly in the network. TCP connections using other algorithms, such as CUBIC, would take over the link completely.
The solution came with a BBR (Bottleneck Bandwidth and Round-trip propagation time), a new algorithm for detecting congestion in TCP.
In short, the BBR algorithm tries to saturate the link more and more while monitoring the increase in delays. When it comes to the point where delays increase drastically, it tries to gently reduce transmission until delays have reasonable value. Thanks to this, when the transmission:
• does not lose packets, the bandwidth is similar with a few times lower delays,
• loses packets, throughput can be even several times higher.
The use of a new congestion handling algorithm in TCP allows you to keep the buffer capacity of network devices low and thus keep the packet delays low, even with a lot of traffic. For some services this is really very important.
The use of BBR in TCP is also critical for HTTP/2 traffic, where all transmission between the client and the server can take place over one connection. With HTTP/1 this is not so important, because a large number of relatively short connections are opened between the client and server. BBR should be activated from a site that provides a large amount of data, such as application servers.
By default, the CUBIC is activated in RHEL8. Process of activating BBR is very simple and is shown below. As soon as we do this, all new connections will use it.

Above we have activated BBR only temporarily. In production, please make sure that these settings will work after restarting the system.
Finally, it is worth adding that the Google is a founder of the BBR algorithm, which successfully uses it on its cloud platform. More about how the BBR algorithm works along with interesting comparisons, tests and charts can be found on the Google blog⁶ and the APNIC blog⁷.
More about what’s new in RHEL8 will be available in:
- Safer DNS, e-mail and other improvements of RHEL 8 – Part II,
- Web-based management interface, sessions recording. RHEL 8 part III,
- RHEL 8 for data centers and cloud environments. What you should know. RHEL 8 part IV.
—
¹ https://access.redhat.com/support/policy/updates/errata
² https://lwn.net/Articles/737771/
³ https://blog.cloudflare.com/how-to-drop-10-million-packets/
⁴ https://engineering.fb.com/open-source/open-sourcing-katran-a-scalable-network-load-balancer/
⁵ https://cilium.io/
⁶ https://cloud.google.com/blog/products/gcp/tcp-bbr-congestion-control-comes-to-gcp-your-internet-just-got-faster
⁷ https://blog.apnic.net/2017/05/09/bbr-new-kid-tcp-block/
01:04 PM, Sep 24
Author:

CEO, Network Engineer and System Administrator at networkers.pl
Marcin Ślęczek
Marcin works as CEO, Network Engineer and System Administrator at networkers.pl, which designs and implements IT Systems, Data Centers and DevOps environments. networkers.pl also sells software and hardware for building such environments and is a partner of well-known manufacturers such as Red Hat, Cisco Systems, IBM, Storware and VMware.